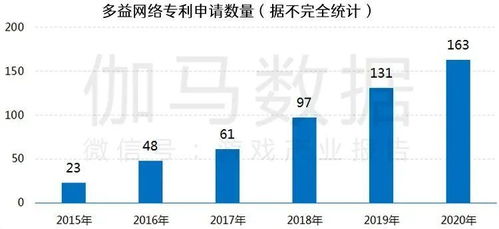
美國華盛頓大學的研究團隊在語音識別與機器翻譯領域取得了一項突破性進展,成功研發出一種名為“空間語音翻譯”的創新技術。這項技術能夠精準識別并翻譯同一空間內多人同時發出的語音,解決了長期以來困擾遠程會議、跨國協作和實時通信的“雞尾酒會效應”難題。
技術原理:聲學與算法的深度融合
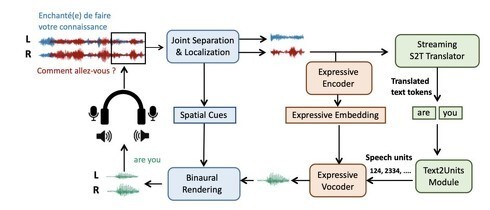
“空間語音翻譯”技術的核心,在于將先進的聲學空間感知技術與深度神經網絡翻譯模型進行深度融合。研究團隊利用分布式麥克風陣列,配合創新的聲源分離算法,首先在物理層面將混雜的語音流依據聲源的空間位置進行分離和增強。這類似于人耳利用雙耳效應在嘈雜環境中聚焦于特定說話者。
分離出的每一條純凈語音流被送入一個經過海量多語言語料訓練的自適應神經網絡翻譯引擎。該引擎不僅能進行高準確率的語音轉文本識別,還能根據上下文和說話者的語言習慣,進行近乎實時的多語言互譯。最關鍵的是,系統通過獨特的“說話者ID”跟蹤技術,能將翻譯后的文本或語音,準確地“投射”回虛擬會議界面對應的原始發言者位置或頭像上,實現了“誰在說、說什么、譯什么”的清晰對應。
應用前景:重塑網絡通信與協作模式
這項技術的潛在應用場景極為廣泛,將深刻重塑未來的網絡通信模式:
- 跨國遠程會議與協作:在擁有多位不同母語參與者的國際視頻會議中,系統可以實時提供每位發言者的翻譯字幕或同聲傳譯音頻,且互不干擾,極大提升溝通效率,打破語言壁壘。
- 沉浸式教育與培訓:在全球性的在線課堂或研討會上,學生和講師可以自由地用母語提問與回答,系統提供無縫翻譯,創造真正無國界的學習環境。
- 國際活動與媒體直播:在新聞發布會、國際賽事或多語種網絡直播中,可為不同語言的觀眾提供個性化的實時解說或字幕服務。
- 智能客服與公共服務:在機場、醫院、跨國企業的客服中心,可幫助服務人員同時處理多位不同語言顧客的咨詢。
- 社交娛樂與虛擬空間:在元宇宙、多人在線游戲等虛擬社交場景中,實現全球用戶無障礙的實時語音交流。
網絡技術研發的協同挑戰與未來方向
“空間語音翻譯”技術的落地與普及,也對底層網絡技術研發提出了新的要求與挑戰:
- 高帶寬與低延遲傳輸:多路高質量音頻流及翻譯數據的同時傳輸,需要更強大的網絡帶寬保障。而實時交互場景對端到端的延遲極為敏感,這推動了5G-A及6G網絡中超低延遲通信技術的研發。
- 邊緣計算與云計算協同:為了降低延遲并保護隱私,部分聲學處理和初步識別任務可在用戶終端或網絡邊緣完成,而復雜的翻譯模型推理則可能依托云端強大的算力。這需要研發更高效的云邊端協同計算架構。
- 數據安全與隱私保護:處理多人的實時語音數據涉及嚴峻的隱私安全問題。未來的研發需集成同態加密、聯邦學習等隱私計算技術,確保語音數據在傳輸和處理過程中得到充分保護。
- 標準化與協議兼容:為了使該技術能廣泛應用于各種會議軟件、通信平臺和硬件設備,需要產業界共同推動相關音頻格式、傳輸協議和接口的標準化工作。
華盛頓大學的這項突破,標志著人機交互和跨語言通信向前邁出了關鍵一步。它不僅是人工智能在感知智能和認知智能結合上的典范,也作為一項前沿的網絡應用,倒逼和牽引著底層網絡技術的革新。隨著技術的不斷成熟和網絡基礎設施的持續演進,“空間語音翻譯”有望像今天的實時字幕一樣,成為全球數字生活中一項不可或缺的基礎服務,讓人類在數字空間中的溝通真正實現“天涯若比鄰,言語皆可通”。